Better Ducking for Voiceovers & Podcasts
By Craig Anderton
Background music or environmental sounds are usually an essential part of commercials, movies, presentations, podcasts, and more. When doing vocal work for these kinds of projects, it’s crucial to attain the correct balance between the voice and the background.
The background level generally needs to duck under the voice when it’s present, and come back up when the voice is absent. With traditional ducking, a compressor processes the background. The voice provides a sidechain signal to the compressor. When the voice is present, it compresses the background. So, its level is lower than the voice.
This tip describes how to use dynamic EQ as an alternate, equally automatic approach that can produce more natural-sounding results. A standard compressor compresses all frequencies. Dynamic EQ can compress only the frequencies that affect vocal intelligibility…which is pretty cool.
First, Analyze Your Voice
Insert the Spectrum Meter in the voice track, after any EQ (if present). Use the settings shown in fig. 1. Play through the narration with the Spectrum Meter’s Hold parameter set to infinity. The resulting curve will show an overall average of the voice’s spectral energy. The cursor can identify where the peak responses occur. Most of my vocal energy falls in the 100 to 600 Hz range, with peaks around 1.3 and 3.5 kHz.
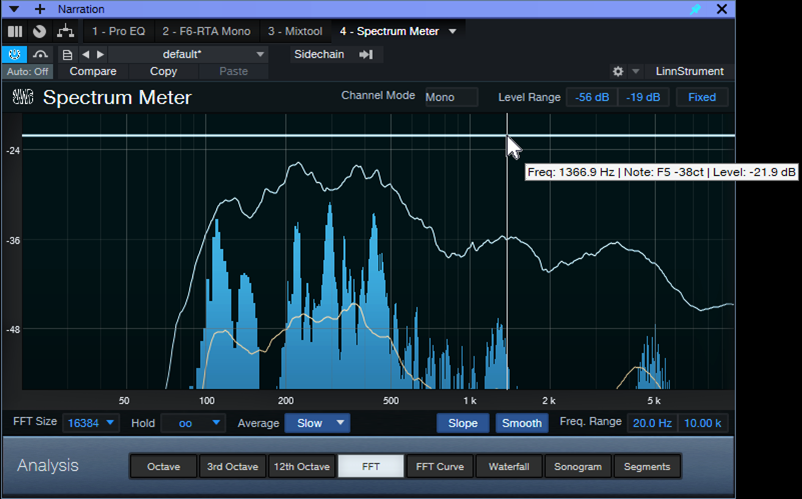
Figure 1: Spectral energy distribution for my voice. Placing the crosshairs over the curve shows the frequencies for various peaks.
Next, insert a Pro EQ3 in the soundtrack’s audio track. Add a pre-fader send to the voice track, and route the send to the Pro EQ3’s sidechain (fig. 2).
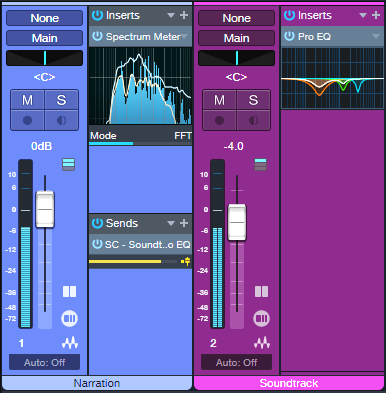
Figure 2: The voice drives the Pro EQ3’s dynamic response via a sidechain.
Finally, create a curve in the Pro EQ3 that’s the inverse of your vocal spectrum. Choose the frequencies you want to reduce, and the appropriate bandwidth for those frequencies. Set negative Range values to determine how much the frequency ranges will be cut. Then, set the Thresholds so that the voice’s peaks trigger the desired amount of gain reduction over that range. Now, the voice’s dynamics will push down the soundtrack’s frequencies that correlate with vocal intelligibility.
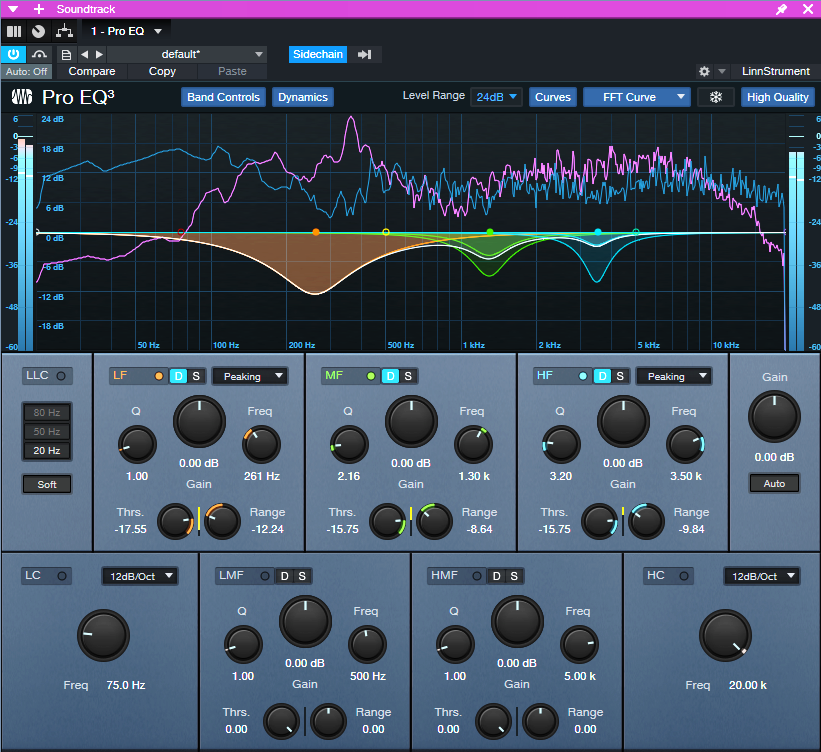
Figure 3: Typical dynamics settings for the Pro EQ3. The dips reduce peaks in the voice’s spectral energy distribution.
To quiet down all soundtrack frequencies when the voice is present, compression is still the best solution. But when you want a scalpel instead of a sledgehammer to produce a more natural ducking effect, try using dynamic EQ.
Now, if only the people mixing movie sound start doing this so we can understand the dialog…!