Author Archives: Craig Anderton
Avoid Collaboration Concerns

By Craig Anderton
As the universe of Studio One users grows, so do opportunities for collaboration. But your collaborator may not be using the same version of Studio One as you—it could be a version of Artist that came with an interface, or the latest and greatest version of Studio One Professional. Or maybe the program wasn’t updated for some reason, like cash flow issues, or being dependent on ReWire. Fortunately, most of the time projects done in one version of Studio One can translate to other versions. So, here are some guidelines to keep in mind when collaborating.
Resolving Song Formats
Songs are generally incompatible with previous Studio One versions. However, you don’t have to transfer an entire song file. Use Export Mixdown to generate a rough premix. Whoever wants to record an overdub(s) can do so while listening to the premix. Then, the overdub stems can be exported as audio files, and added to the original project.
It’s crucial that all files have the same start point. For example, if there’s a solo halfway through the song, extend the solo’s beginning by drawing a blank section with the Paint tool. Then, bounce the blank beginning and the overdub together before exporting the stem.
Third-Party Plugin Issues
I prefer using as many native Studio One plugins as possible, not only because it’s a solid selection, but because that minimizes the chance of needing third-party plugins that one or the other person doesn’t have. However, for third-party plugins, this is an instance where subscription-based software can work in your favor. You may be able to subscribe to the plugins you don’t have for long enough to use them in a project, and then stop subscribing.
Using Professional FX Chains in Artist
If the FX Chain consists of a serial chain of effects, and both collaborators have the same plugins, the FX Chain will be compatible with both Professional and Artist. Although there’s no Channel Editor or Macro Controls in Artist, users can take advantage of the Micro Edit view in the mixer or in the Channel Overview (fig. 1). This allows editing several important parameters without having to open effects in the chain.
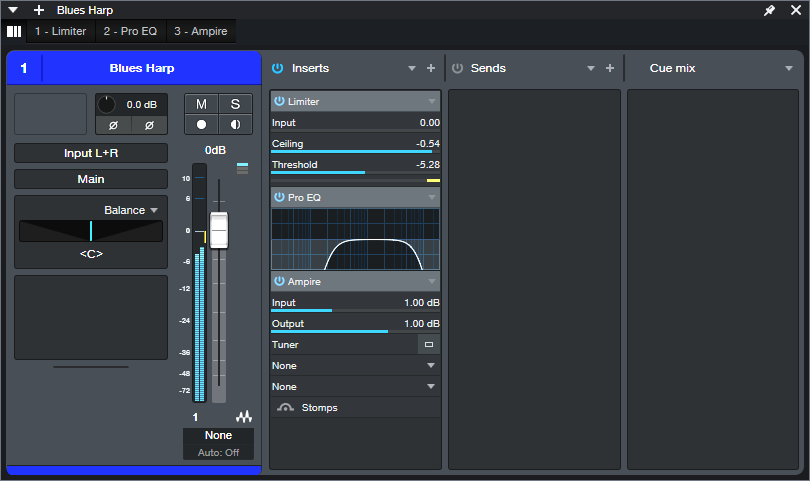
Figure 1: The Micro Edit view is useful for quick edits when the Channel Overview is open.
Missing Plugin: If an Artist user is missing a plugin you have in Professional, they’ll see an error message like fig. 2.
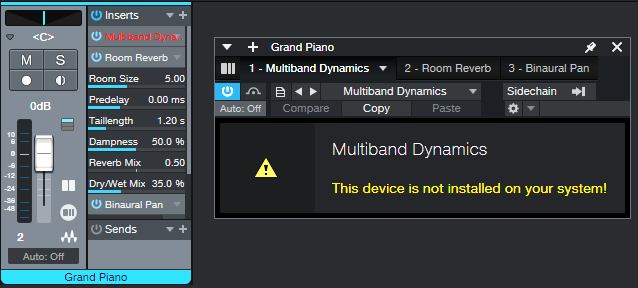
Figure 2: Studio One Artist doesn’t include the Multiband Dynamics processor.
This is helpful, because you can then substitute a plugin that gives a sound close to what’s needed (in this case, the Tricomp may work), create a new FX Chain, and send it to your collaborator.
FX Chains with a Splitter: Artist doesn’t include the Splitter, so it won’t recognize parallel paths in a Professional FX Chain that incorporates a Splitter. Instead, Artist rearranges the FX Chain to put all the effects in series (fig. 3). Note that there’s no error message to alert the user there’s a potential problem.
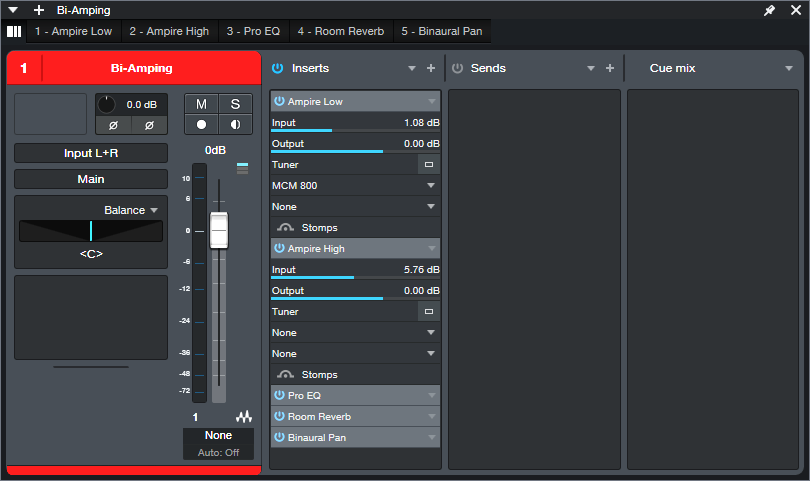
Figure 3: Originally, a frequency-based Splitter bi-amped two Ampires in parallel. Artist translated the chain into a series chain of effects that placed the two Ampires in series, without a way to bi-amp them.
In a case like this, when you send a song file, put as many of the series effects as you can in an FX Chain. In Artist, you would then use an input track and buses to split the audio (fig. 4).
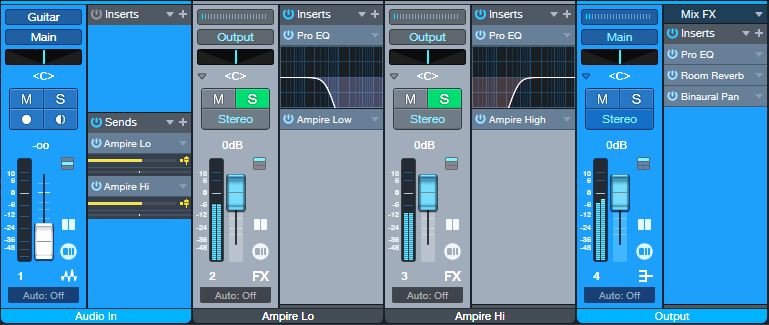
Figure 4: To replace frequency-split functionality, the Audio In channel splits the audio by sending it to two FX Channels. Each FX Channel has a Pro EQ3 to split based on frequency, which then feeds an Ampire. The Output channel includes the post-Ampire effects. You can save these as an FX Chain.
Even though the effect order changes in Artist, the effect parameter settings remain intact. If the user knows what the routing is supposed to be, simply create a track layout with the required tracks and buses, and drag the effects from the FX Chain that loaded in Artist to the additional tracks and buses. (This can get messy if there are several frequency splits, but it’s still doable with a stand-alone splitter plugin like TB Pro Audio’s ISOL8.)
FX Chain Backward Compatibility with Studio One Professional
Assuming the source and target programs have the same plugins used in the FX Chain, backward compatibility is rarely an issue.FX Chains created in Studio One 6 can load in versions 3, 4, and 5 (FX Chains didn’t exist before version 3). However, version 3 was before the Splitter was introduced. So, Studio One 3 Professional rearranges FX Chains with a Splitter into a series connection, the same way Artist does. You’d resolve the issue the same way you would in Artist. But seriously—if you’re collaborating with some who uses Studio One 3, gently suggest that they stop buying coffee at Starbucks for a while, and at least get Studio One 6 Artist.
Studio One Professional Track Preset Compatibility
Track Presets are exclusive to Studio One Professional. Also note that Track Presets were introduced in version 6, so as expected, they won’t load in previous versions.
When dealing with Studio One Artist users (or Professional users who haven’t installed version 6 yet), deconstruct any Track Preset you use into its components (similarly to fig. 4 above). Take a screenshot and send that to your collaborator.
Of Course, the Best Solution is Staying Updated
Given how many free updates there are between Studio One versions, there’s really no reason not to update. But sometimes, you’ll run into situations where for one reason or another, someone hasn’t updated their program or is using a different version—and now you have some solutions for carrying on with your collaboration.
Create Rhythmic Alchemy with the BeatCoder

By Craig Anderton
Over three years ago, I wrote a blog post on how to make a “drumcoder.” Its design was somewhat like a vocoder—drum audio served as a modulator for a carrier (e.g., a synth pad or guitar power chord). However, because the goal was not to process voice, the sound was warmer and more organic than traditional vocoding.
Unfortunately, the effect was super-complex to put together, and was practical only if you had Studio One Professional. But, no more: Dynamic EQ can take the concept to the next level. The BeatCoder is a much improved—and far simpler—version of the Drumcoder. Even better, it works with Studio One Artist and Professional. Let’s take a listen…
Fig. 1 shows one way to do BeatCoding.
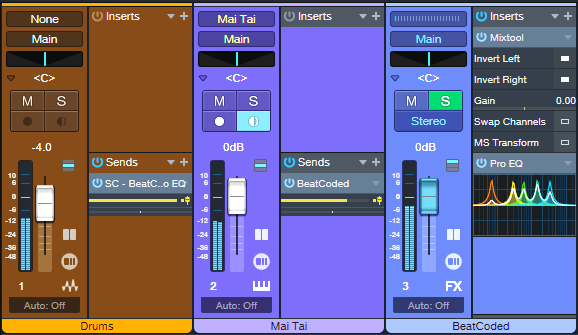
Figure 1: BeatCoder channel layout.
Let’s look at the Mai Tai “carrier” first. The Mai Tai track (or other sound of your choice) typically provides a sustained pad or similar sound. A Send goes to the BeatCoded FX Channel, which is in parallel with the Mai Tai and includes a Mixtool. The Mixtool inverts the left and right channels, so the BeatCoded track is out of phase with the Mai Tai. This causes the carrier sound to cancel.
The magic happens because of the Pro EQ3 in the BeatCoded track. The Drums track has a pre-fader send that feeds the Pro EQ3’s sidechain. By using the Pro EQ3’s Dynamic mode (fig. 2), the drum dynamics boost particular frequencies in the BeatCoded track in time with the beat. In the audio example, you’ll hear a drum loop driving the dynamic EQ as it processes a Mai Tai pad.
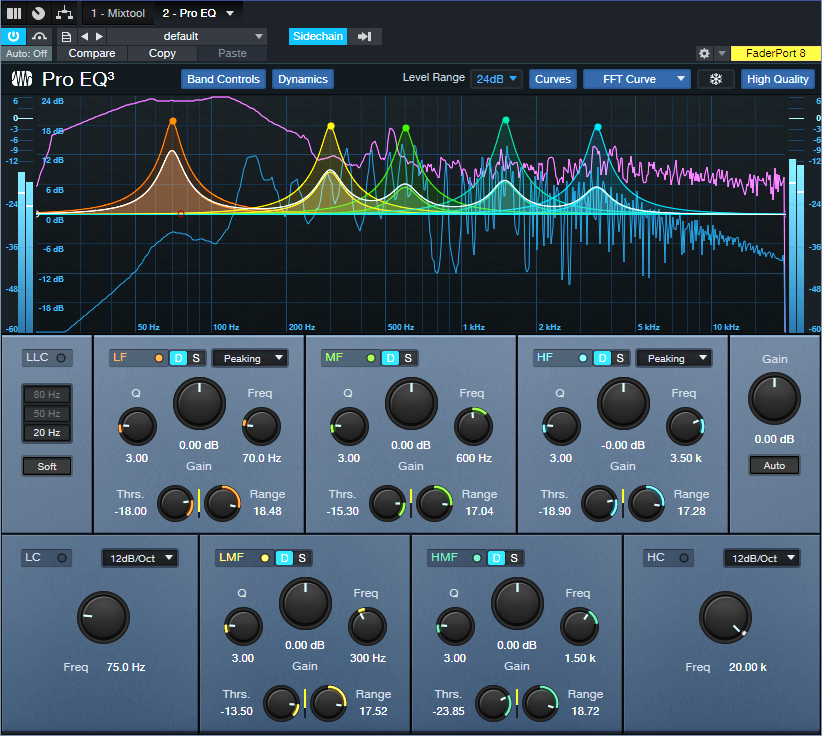
Figure 2: EQ settings used in the audio example.
Editing the Parameters
The editing possibilities are enormous:
- The EQ frequencies can cover various ranges. The Low and High Shelf EQs are in play as well as the Peaking filter type. You can even tune the EQ stages to different drums to have the synth sound respond super-tightly to the drum sounds.
- Higher Q settings are more dramatic, but can lead to overloads. Trim the synth/pad/power chord’s level if needed. You may also need to trim the Pro EQ3’s output level if the peaks distort.
- Each stage’s Range sets how much boost the EQs will receive from drum frequencies in the stage’s range. Threshold sets the level above which the drums affect the EQ.
- The Solo buttons for the various EQ stages help when getting to know this effect. They make it easy to set the Threshold and Range for a balanced response to dynamics (assuming that’s what you want).
- The pre-fader Send from the Drums track adjusts the amount of cancellation. Moving it off center lets through more of the synth sound. This is a very sensitive control, so it’s easy to miss where there’s maximum cancellation.
- Note that it’s not possible to have total cancellation, so that you hear only the effect of the EQ. EQs based on analog modeling have unavoidable phase shifts, which causes some leakage between the bands.
Other Implementations
The implementation shown above is simple and flexible, but it’s not the only one.
- You could create an FX Chain with the plugins from the BeatCoder track in fig. 1, insert the FX Chain in an Instrument track, and save the combination as an Instrument + FX preset. The Pro EQ3’s sidechain would still be accessible to an audio track with drums or a different audio source.
- The Pro EQ3 sidechain acts like a bus, because it can receive multiple inputs. So, if a drum module had individual outputs, particular drums could feed the sidechain selectively.
- The Range can also go negative, where the drums cut the response instead of boost it. This creates a more subtle effect, but can be useful in ambient and other forms of chill music.
Take the time to set this up, and play with it for a while. Warning: The results can be habit-forming.
Make Stereo Downmixes More Immersive

By Craig Anderton
One of Atmos’s coolest features is scalability. No matter how complex your Atmos project may be, you can render it as Binaural, 5.1, 5.1.2, 7.1, etc.—or even as conventional stereo.
As mentioned in a previous blog post, I now release Atmos Binaural and Stereo versions of my music on YouTube. However, although downmixing to stereo from Atmos retains the instrumental balance well, the frequency response seems a bit off compared to Atmos Binaural.
So, I used iZotope’s Tone Balance Control 2 to figure out what was happening. This analysis plugin is the result of dissecting thousands of master recordings. It shows a frequency response range within which different musical genres fall.
Fig. 1 shows the response curve of the downmixed stereo file derived from an Atmos mix. This is what most of my mixes look like before they’re mastered. Here. it pretty much skates down the middle of the “pop” curve.
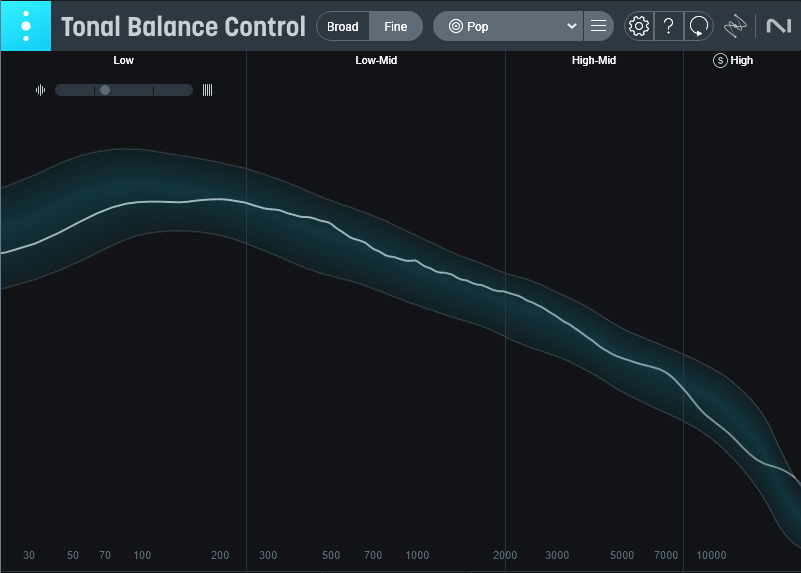
Figure 1: Averaged frequency response curve of the stereo downmix.
Fig. 2 shows the averaged response curve of the Atmos Binaural mix. There are some obvious, and audible, differences.
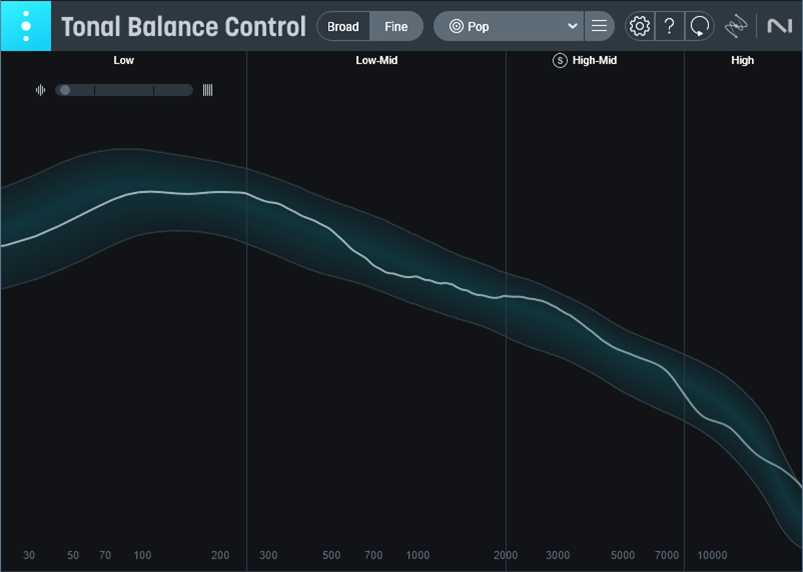
Figure 2: The response curve of the Atmos Binaural render looks semi-mastered.
There’s a small bass bump, a dip in the midrange, and a slight boost in the “intelligibility” region around 2 to 3 kHz. Interestingly, these are like the EQ changes I apply when mastering.
Next, I created a Pro EQ3 curve that applied the same kind of EQ changes to the downmixed stereo file (fig. 3).
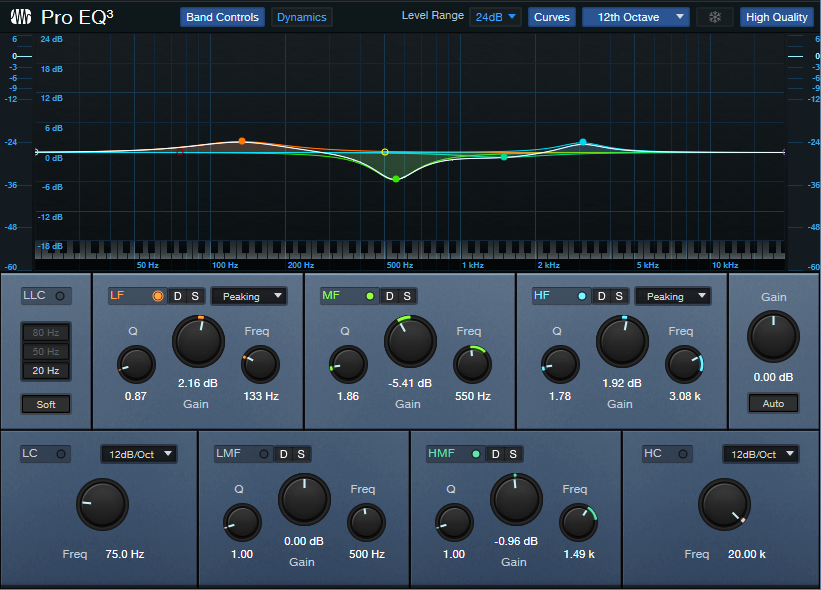
Figure 3: Pro EQ3 compensation curve for making the stereo downmix sound more like the Atmos Binaural mix.
Now the curve is much closer to the Atmos Binaural curve (fig. 4).
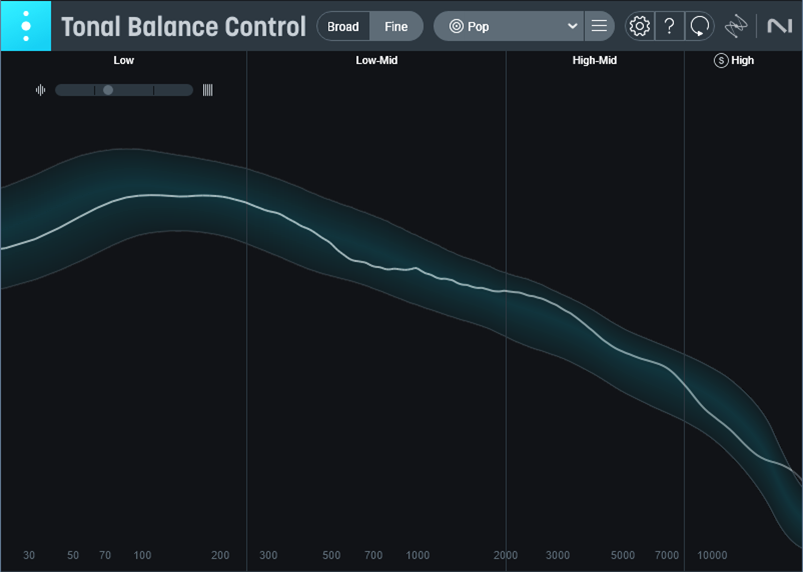
Figure 4: Averaged frequency response of the downmixed stereo file, after applying the compensation curve.
Does this mean that Atmos Binaural is tinkering with the sound? I don’t know. It may be a natural result of trying to translate an Atmos surround-based mix into Binaural audio. It may be a way to tweak the sound a bit to make it more consumer-friendly. That wouldn’t surprise me—most of what plays back music these days hypes the sound. The EQ difference isn’t huge, but it’s enough to give a slight perceived enhancement.
Let’s hear the difference. The audio example plays three 18 second samples of the same part of a song, all adjusted to around -12 LUFS using the Waves L3-16 multiband limiter. The first part is the stereo downmixed file. The second part is the Atmos Binaural file. The third part is the stereo downmixed file, but processed with the EQ compensation curve. Note that it sounds much closer to the Atmos Binaural version (although of course, without the spatial enhancements).
The audio example has drums, voice, guitars, bass, and synth. It’s a representative cross-section of what EQ affects the most in a mix. To my ears, the EQ-compensated downmix is an improvement over the unmastered downmix, and focuses the track a bit better.
So, the next time you want to downmix an Atmos mix to create stereo, consider the above when you want to minimize the difference between Atmos Binaural and stereo. Then, apply whatever other mastering you want to apply to both versions. You’ll end up with stereo mixes that may not have the depth of Atmos Binaural, but they’ll sound a lot closer.
Stamp Out Boring Flanging!

By Craig Anderton
The impetus behind this design was wanting to add envelope flanging to amp sims like Ampire. But there’s a problem: most amp sim outputs don’t create enough dynamics to provide decent envelope control. Well, that may be true in theory—in practice, though, Studio One has a few tricks up its sleeve.
How It Works
The Envelope Flanger is based on marrying a Track Preset with an FX Chain, and raising a family of Autofilters. Fig. 1 shows the FX Chain’s routing window.
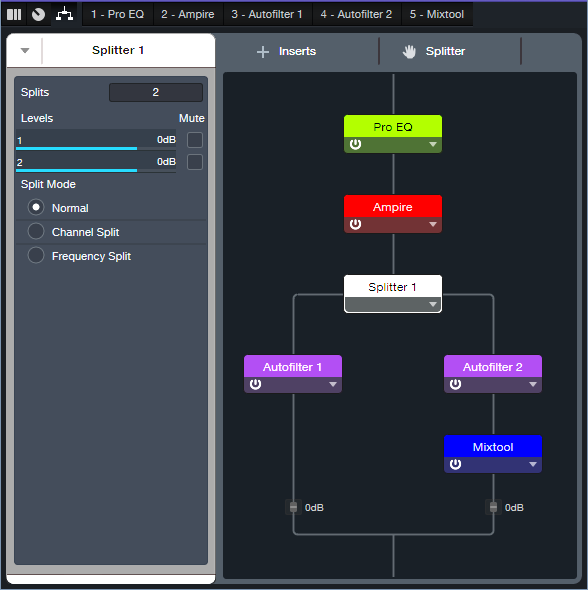
Figure 1: Flanger section for the envelope-controlled flanger.
The optional Pro EQ3 limits the high and low frequencies going into Ampire, which I feel gives a cleaner distortion sound. The Splitter feeds two Autofilters, which use the Comb filter configuration to create flanging. After all, the flanging effect creates a comb filter response, so we can return the favor and use comb filters to create a flanging effect.
To produce the “sucking,” negative-flanging sound, the two Autofilters need to be out of phase. So, the Mixtool Inverts the left and right channels for Autofilter 2.
The Track Preset
The reason for having a Track Preset (fig. 2) is because normally, the Autofilter responds to dynamics at its input. However, when preceded by an amp sim with distortion, there aren’t any significant dynamics. So, the Audio In track has two Sends. The upper Send in fig. 2 feeds audio to the FX Chain. The lower Send controls the sidechain of one of the AutoFilters. This allows the Autofilter to respond to the original audio’s full dynamics, rather than the restricted dynamics coming out of an amp sim.
Figure 2: The Track Preset, which incorporates the FX Chain.
Editing the Autofilters
Like any envelope-controlled processor, it’s necessary to optimize the settings that respond to dynamics. In fig. 3, the crucial Autofilter controls are outlined in white. However, they also work in tandem with the Send from the Audio In track that feeds the Autofilter sidechain. Adjusting this Send’s level is crucial to matching the flanger response to your dynamics.
It’s unlikely you’ll have the sound you want “out of the box,” but be patient. As you’ll hear in the audio example, when matched with your dynamics, the envelope flanging effect will do what you want.
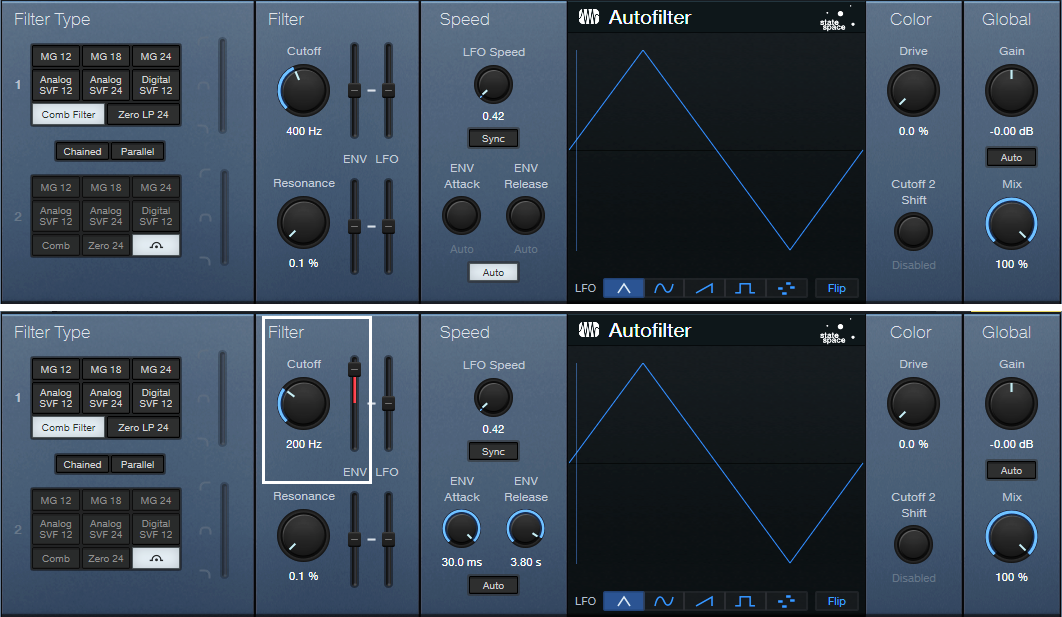
Figure 3: Initial Autofilter settings for Autofilter 1 (top) and Autofilter 2 (bottom).
Except for the Env slider in Autofilter 2, the Env and LFO sliders need to be at 0. To zero them, cmd/ctrl+click on the sliders. Depending on the Autofilter settings, the flanging envelope can either:
- Follow a string’s decay (positive-going response), where higher amplitudes raise the flanging pitch from the initial pitch.
- Follow a reverse decay (negative-going response), where higher amplitudes lower the flanging pitch.
- In either case, as the string decays, the flanging returns to its initial pitch.
For a positive-going response, start with the settings in fig. 3, but expect that you may need to change them. Set Autofilter 2’s Cutoff to a lower frequency than the Autofilter 1 Cutoff. Use positive Env modulation. Choose an Env modulation setting that reaches a high frequency, but doesn’t go so high that it starts cancelling on peaks consistently and sounds uneven. (However, some occasional cancellation gives the coveted “through-zero” flanging effect.) Vary the sidechain’s Send slider to optimize the response further.
For a negative-going response, change Autofilter 1’s filter Cutoff to 200 Hz. Fig. 4 shows Autofilter 2’s initial filter Cutoff setting, which should be just above where through-zero cancellation occurs after a string decays. But really, you don’t have to be too concerned about this. Play around with the two Cutoff controls, the Send fader, and Autofilter 2’s Env modulation amount…you’ll figure out how to get some cool sounds. Just remember that these controls interact, so optimization requires some tweaking.
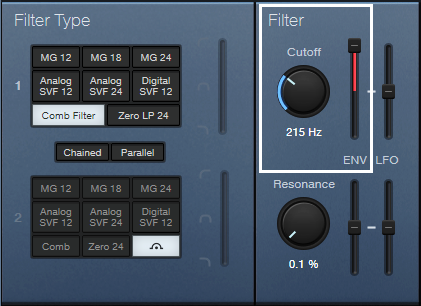
Figure 4: Autofilter 2’s settings that relate to negative-going flanging.
Here’s an audio example. The first half is positive-going envelope flanging, the second half is negative-going.
Download the Envelope Flanger.trackpreset here.
Creating Room Ambiance with Virtual Mics

By Craig Anderton
Supplementing close-miking techniques with room mics gives acoustic sounds a life-like sense of space. Typically, this technique involves placing two mics a moderate distance (e.g., 10 to 20 feet) from the sound source. The mics add short, discrete echoes to the sound being mixed.
This tip’s goal is to create virtual room mics that impart a room sound to electronic or electric instruments recorded direct, or to acoustic tracks that were recorded without room mics. Unlike a similar FX Chain-based tip from over six years ago, this Track Preset (see the download link at the end) takes advantage of a unique Track Preset feature that makes it easier to emulate the sound of multiple instruments being recorded in the same room.
The following trackpreset file will only work with Studio One Professional and Studio One+.
Using the Track Preset
Load the Track Preset Virtual Room Mics.trackpreset (Studio One+ and Professional only). After opening the Mixer view, in Small view you’ll see an audio track and four FX buses (fig. 1).
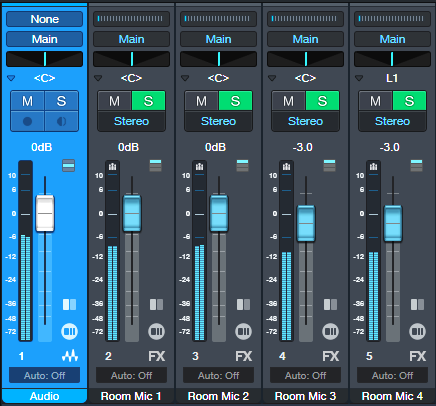
Figure 1: The Track Preset in the Mixer’s Small view.
The Track Preset includes a stereo audio track. This hosts the sound you want to process. Its four sends go to four FX Channels, each with an analog delay set for a different, short delay time (11, 13, 17, and 23 ms). These are prime numbers so that the delays don’t resonate easily with each other. The delayed sounds produce a result that’s similar to what room mics would produce.
The FX Channels are grouped together, so altering one Room Mic fader changes all the Room Mic faders. The levels are already offset a bit so that longer delays are at a slightly lower level. However, you can edit individual Room Mic faders by holding Opt/Alt while moving a fader. Note: Because the faders are grouped, you can simplify the Mixer view by hiding Room Mics 2, 3, and 4. Then, the remaining Room Mic 1 FX Channel controls the ambiance level.
Under the Hood
Fig. 2 shows the expanded Track Preset.
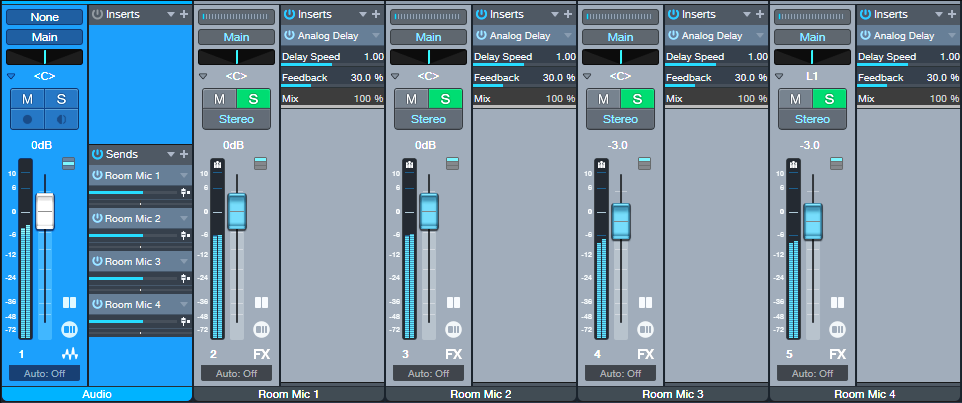
Figure 2: Expanded Track Preset view.
The Audio track has four post-fader sends. Each goes to its own virtual mic FX Channel with an Analog Delay. Aside from the delay times, they all use the settings shown in fig. 3.
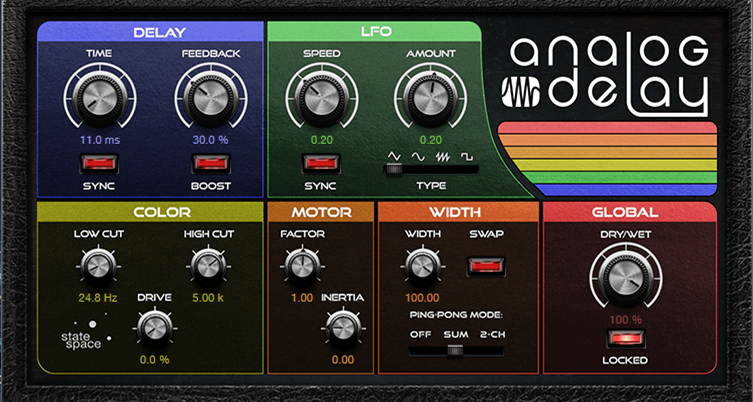
Figure 3: This shows the delay that’s set to 11 ms. The other delays are set identically, except for the delay time.
Using the Virtual Room Mics with More Than One Track
Loading another Virtual Room Mics.trackpreset does not load four more FX Buses. Instead, a new track appears, with its Sends already configured to feed the existing FX Buses. So, you can treat the Virtual Room Mics.trackpreset as a single room for multiple tracks.
Because new tracks appear with Sends already configured, you can vary the send levels slightly for different tracks to place the instruments in different parts of the room. For example, to move the instrument closer to the listener, turn down the sends going to room mics 3 and 4 (with the longest delays), and turn up the sends going to room mics 1 and 2 (with the shortest delays). To place the instrument further away, do the reverse. This more closely emulates recording multiple instruments in the same room. It’s a cool feature of Track Presets used in this type of application.
Workflow Tips
To hear what this FX Chain can do, load a mono Audioloop like Pop > Guitar > Dry > 01a Basement Jam E min. You’ll hear the guitar playing in a room, with a lifelike stereo image.
The main use for this Track Preset is when mixing a combination of acoustic instruments that are miked in a room, and electronic or electric instruments that are recorded direct. Adding room ambiance to the sounds that are recorded direct will let them blend better with the acoustic sounds. It’s best to insert this Track Preset early in the mixing process, so that your mix starts with a consistent acoustic space.
Don’t Make This Mixing Mistake!

By Craig Anderton
Do you think of mixes in absolute terms, or relative terms? Knowing the difference, and when to apply which approach, can make a huge difference in how easily mixes come together. This can also affect whether you’re satisfied with your mixes in the future.
Mixing is about achieving the perfect balance of all of a song’s tracks. When you start mixing, or if you mix in parallel with developing a song, your mixing moves are absolute moves because you haven’t set up the relationship among all the tracks yet. For example, the guitar might be soft compared to the drums and bass, so you increase the guitar’s level. At that point, you don’t yet realize that when a piano becomes part of the mix, the guitar will mask it to some degree. So, now you’ll need to readjust the guitar’s level not only with respect to the drums and bass, but also in relation to the piano.
The further your mix develops, the more important the relative balance among all the levels becomes. Remember: Any change to any track has an influence on every other track. I can’t emphasize that enough.
A Different Way to Finish a Mix
At some point, your mix will be “almost there.” That’s when you notice little flaws. The drums are a bit overpowering. The bass needs to come up. The background singers don’t have quite the right balance with the lead vocal. Two keyboard parts are supposed to be the same level, but one is slightly louder.
The absolute approach to addressing those issues would be to make those changes. The kick comes down a bit. The bass comes up. You balance out the background singers and the keyboards. Then you render another mix to see if the problems have been addressed. It’s better, but now the bass is masking the low end of the keyboards. So, you bring up the keyboards a bit, but now they step on the background vocals…
If you’re not concentrating on how the tracks fit together in relative terms, then you’ll constantly be chasing your tail while mixing. You’ll keep making a series of absolute adjustments, and then wonder why relatively speaking, the mix doesn’t gel.
The Relative Approach to Mixing
VCA Channels are the key to relative mix edits, because they can offset tracks easily compared to the rest of the mix. Take the example above of the drums being a bit overpowering, the bass too soft, etc. Rather than try to fix them all at the same time, here’s what I do:
1. Choose the issue that seems most annoying. Let’s suppose it’s the drums being overpowering. I always start with fixing tracks that are too loud instead of too soft, because lowering the level of the loud track will make all the other tracks louder, relatively speaking.
2. Select the drum tracks (or drum bus) and choose “Add VCA for Selected Channels.”
3. Lower the VCA channel for the drums by (typically) -0.5 dB, but no more than -1.0 dB.
4. Not change any other track levels. Now it’s time to render a new version of the mix, and live with it for a day.
Having softer drums will change the relative perspective of the entire mix. Maybe the bass wasn’t that soft after all; maybe it was just masked a bit by the kick. Maybe the rhythm guitar is actually louder than it seemed, because its percussive strums were blending in with the drum hits—but the strums weren’t noticeable until the drums were softer. And so on.
That -0.5 dB of difference will change how you hear the mix. -0.5 dB may not seem like much, but that’s just one perspective. A different perspective is that it’s making every other track +0.5 dB louder than the drums. So, you need to evaluate the mix with fresh ears, because that one change has altered the entire mix.
An advantage of using VCA channels is that when you add the VCA Channel, its initial setting is 0.0. It’s easy to see how much you’ve offset the track level with the VCA, compared to (for example) changing a drum bus fader from -12.6 to -13.1. It’s also easy to get back to where you started in case after listening to the track, you decide other tracks were the problem, and the drums need to return to where they were. Just reset the VCA to 0.0.
Let’s suppose that after listening to the rendered version a few times at different times of the day, it seems like the drums fit in much better with the overall mix. Make the change permanent by de-assigning the tracks to the VCA Channel, and then removing the VCA Channel. (Or, leave it in and hide it if you think you might need more changes in the future.)
Next, let’s suppose the bass still seems a little soft. I’ll repeat the four steps listed above, but this time with the bass track, and raise it by +0.5 dB (fig. 1). Then it’s time to render the track again, and live with it for a day.
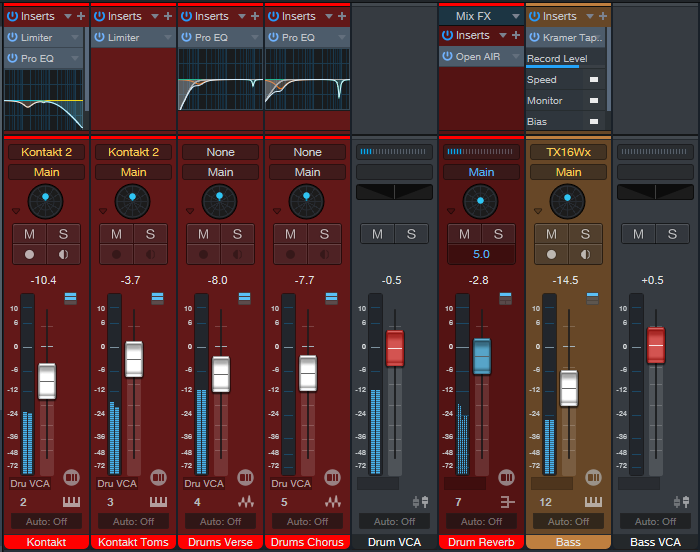
Figure 1: A VCA channel has altered the drum mix by -0.5 dB. That VCA Channel is about to be removed, because -0.5 dB turned out to be the right amount. Meanwhile, a VCA Channel has been added to see if increasing the Bass level by +0.5 dB helps it fit in better with the mix.
It might seem that this one-track-at-a-time approach would take forever, especially because sometimes you may need to revise earlier changes. But it can save time, for two reasons:
- Mixing sessions don’t go on for hours. Because you listened to the rendered mix with fresh ears and know what you need to change, you make the change. After rendering the new mix, you’re done for the day, aside from listening to it several times under various conditions. Your final mixes now become 5 to 10 minutes at a time spread over multiple days. An additional advantage is that you always hear the mix with fresh ears, instead of having listener fatigue set in during a long mixing session.
- Often, after taking care of the most problematic tracks, other issues resolve themselves because they weren’t the problem—their relationship to the problematic tracks was the problem. Fixing those other tracks fixes the relationship.
If after repeated listening over a few days (and being brutally critical!) I don’t hear anything that needs to change, then the song is done.
A Corollary to Relative Mixing
This approach is also one reason why I don’t use dynamics processors in the master bus, except for the occasional preview. All dynamics processors are dependent on input levels. As you change the relationship of the tracks, you’re also changing how a master bus’s dynamics processor influences your mix.
Some people say they need to mix through a dynamics processor, because the mix doesn’t sound right without it. I think that may be due to mixing from an absolute point of view, and the dynamics processor blurs the level differences. I believe that if you achieve the right relative balance without using a master bus dynamics processor, when you do add dynamics processing during the mastering process, the balance will remain virtually identical. Your mix will also gain the maximum benefits from the dynamics processing.
Once you start considering when to employ a relative mixing approach compared to a more absolute approach, I think you’ll find it easier to finish mixes—and you’ll end up with mixes you’re satisfied with years later.
Tuff Beats
By Craig Anderton
Calling all beats/hip-hop/EDM/hard rock fans: This novel effects starts with drums modulating the Vocoder’s white noise carrier, and takes off from there. The sound can be kind of like a strange, aggressive reverb—or not, because the best part of this tip is the crazy variety of sounds that editing or automating parameters can create.
The following audio example plays just a few of the possibilities. The first two measures are the original loop. Then, several 2-measure examples alter Vocoder parameters.
Track Layout
Fig. 1 shows the track layout:
- The Drums track hosts the waveform that modulates the Vocoder via a pre-fader send to the Vocoder track. How you set the Drums track fader depends on whether or not you want to mix in unprocessed sounds.
- The Carrier track generates white noise as a carrier for the vocoder’s sidechain (fig. 2), as sent through a pre-fader send. You’ll probably want to keep the Carrier track’s fader at minimum.
- The Vocoder track produces the processed output to mix in with the drums.
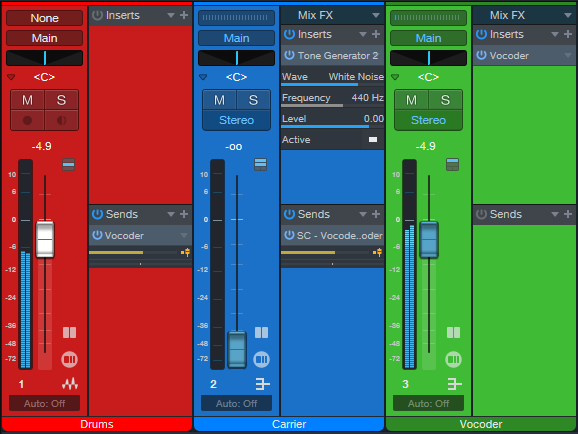
Figure 1: Track layout for Tuff Beats processing.
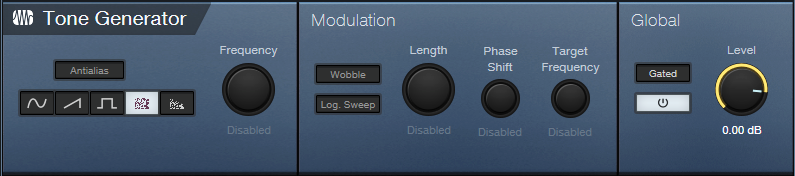
Figure 2: Tone Generator settings.
Editing the Effect
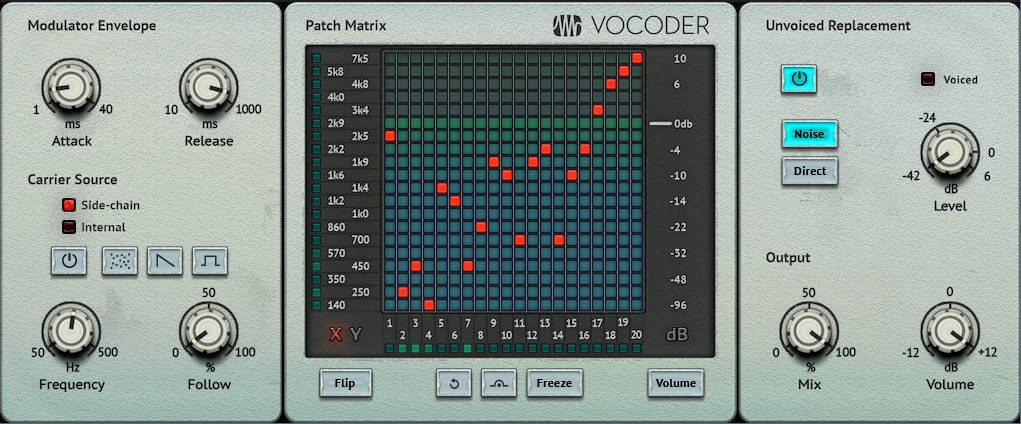
Figure 3: Typical Vocoder settings.
The only crucial setting is that the Carrier Source must be set to Side-Chain (fig. 3). Aside from that, you have plenty of options for subverting the sound:
- Release. At longer release times, the sound is like a strange reverb. Shorter settings are more like doubling.
- Release automation. Try drawing waveform automation with the Paint tool, like negative-going sawtooth waves and triangle waves. Freehand drawing can produce even wilder effects.
- Attack. Turning up Attack reminds me of a transient shaper, because it softens the drum attack.
- Patch Matrix. This alters the “reverb” character. You can get some pretty whacked out filtering effects.
- Matrix automation. Now you can really go insane. Choose Write for the Vocoder’s automation mode, and “draw” on the Patch Matrix as you would an Etch-a-Sketch. This changes the filtering effects, and the automation remembers your moves.
It doesn’t take much effort to come up with some pretty novel sounds, so…have fun!
Reinvent Your Stereo Panning
This tip is about working with stereo, NOT about Dolby Atmos® or surround—but we’re going to steal some of what Atmos does to reinvent stereo panning. Studio One’s Surround panners are compatible with stereo projects, offer capabilities that are difficult to implement with standard panpots, and are easy to use. Just follow the setup instructions below, and start experimenting to find out how surround panning affects stereo tracks. (Surround panners work with mono tracks too, although of course the stereo spread parameter described later is irrelevant.)
Setup
When you’re ready to mix, choose Song > Spatial Audio. Select the parameter values to the left in fig. 1. In the output section (fig. 1 right), select 5.0 for the Bed format, and Stereo for both Speakers and Headphones so you can use either option to monitor in stereo.
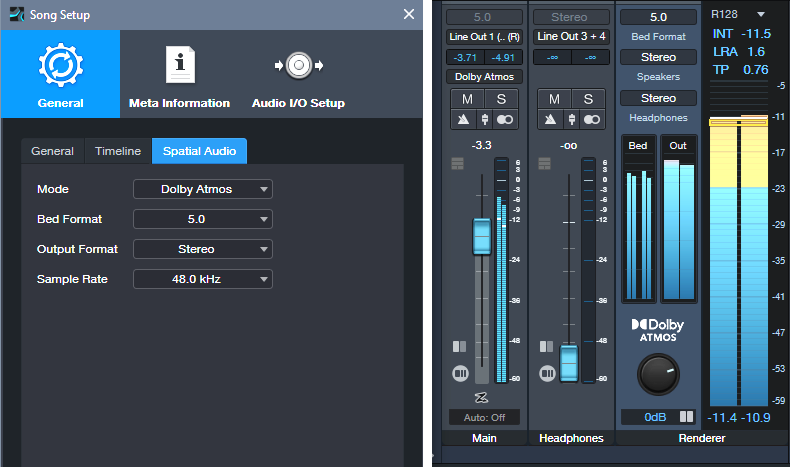
Figure 1: Parameter setup for Surround panning with stereo projects.
After choosing Dolby Atmos for spatial audio, channel panpots turn into surround panpots. Double-click on them to see the “head-in-middle-of-soundfield” image shown below. Choose Disable Center, which isn’t used. LFE Level doesn’t matter, unless you’re using a subwoofer.
Using surround panners for stereo offers several adjustable parameters:
Spread. Move the L and R circles to set the left and right pan position spread, or click and drag in the numeric Spread field. The spread (fig. 2) can go from 0 (mono), to 100% (standard panning), to 200% (extra wide, like binaural panning).
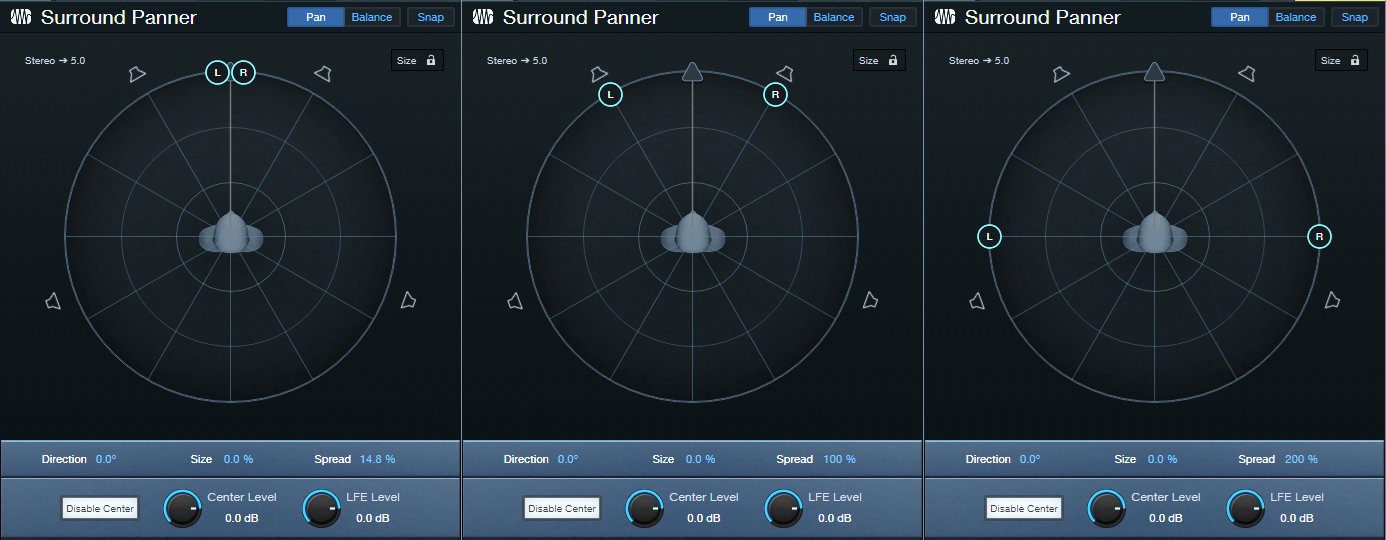
Figure 2: (Left to right) 14.8% spread, 100% spread, 200% spread.
Direction. After establishing the spread, click on the arrow and rotate the spread so it covers the desired part of the stereo field (fig. 3). You can also click and drag on the numeric Direction field. Between spread and direction, you can “weight” the stereo spread so that it covers only a sliver of the stereo field, covers center to right or left, mostly left, mostly right, etc.
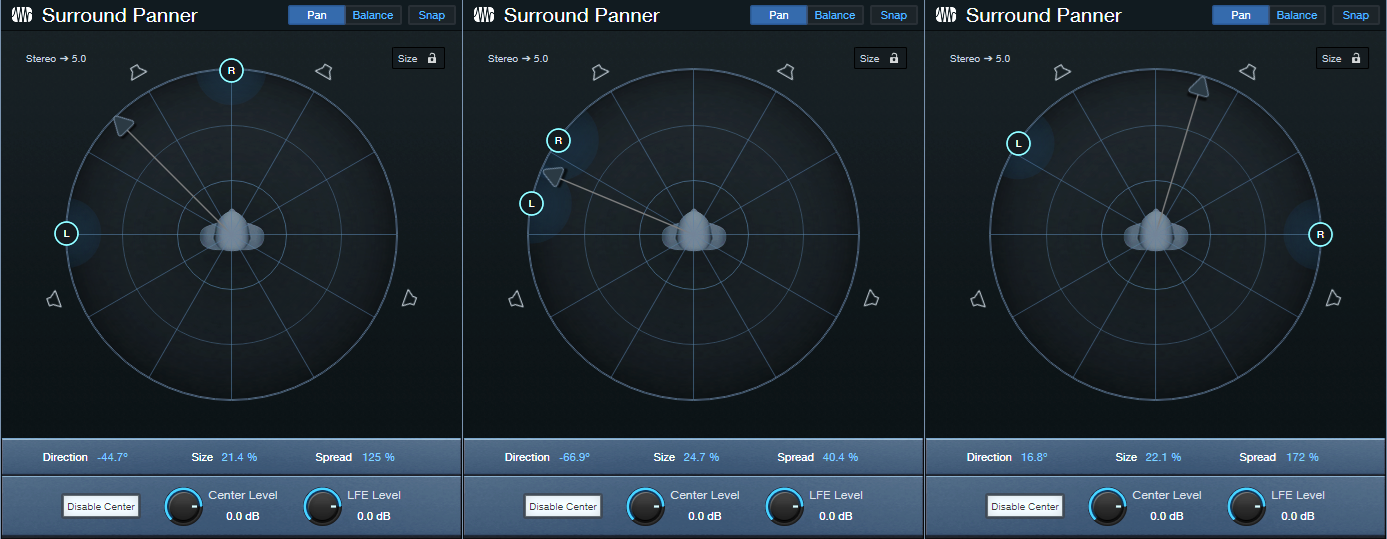
Figure 3: (Left to right) Panned from left to center, panned to a narrow slice of the stereo field, and panned almost full but tilted toward the right.
Size. This has no equivalent with stereo panpots. Click on the arrow, and move it closer to the head for a “bigger” size, or further from the head for a “smaller” size (fig. 4). You can also click and drag on the numeric Size field. The result isn’t as striking as with true surround, but it’s much more dramatic than standard panning. Note the “cloud” that shows how much the sound waves envelope the head. All the previous images showed a small size.
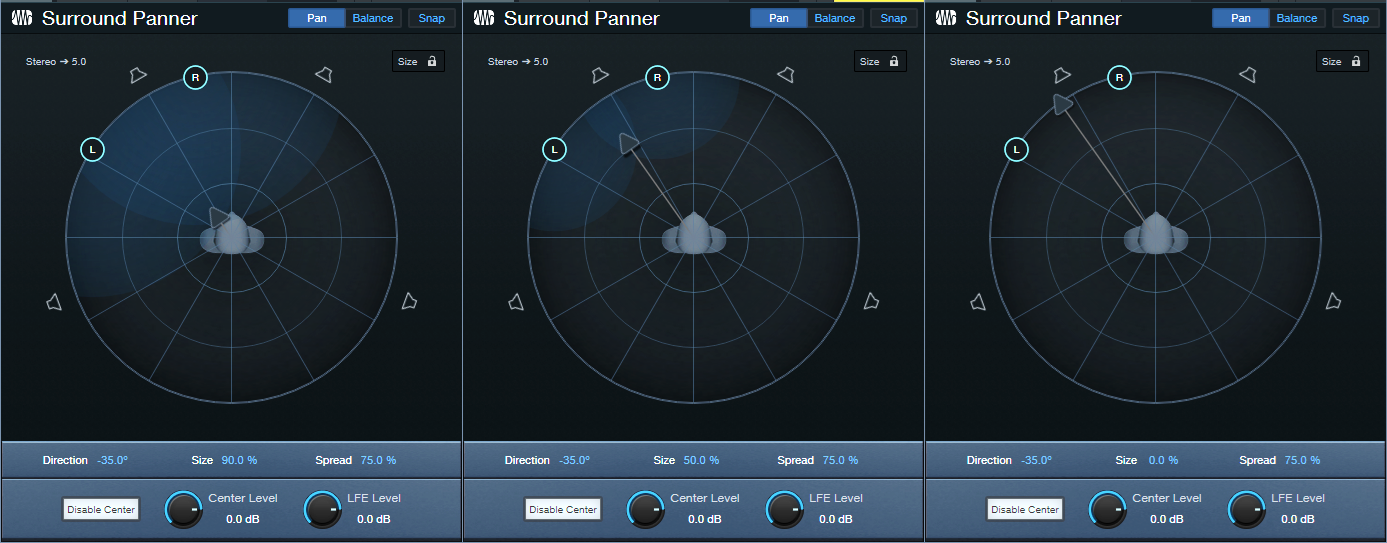
Figure 4: (Left to right) Biggest size/least distance, moderate size/moderate distance, smallest size/furthest distance.
Flexible automation. A joystick or controller pad can automate two of the parameters simultaneously. Or, modulate all three parameters using three controls from a control surface. This is a huge deal compared to standard panning. For example, suppose an instrument is ending a solo, while another solo starts. The one that’s ending can pan to a narrower spread, move off to the side, and become smaller just by moving three controls.
Other Features
- Balance Tab. The surround panners can also serve as conventional balance controls. This setting interacts with the panners. For example, if the L and R buttons are close to each other, there won’t be much balance to adjust. I rarely use the balance option. To make sure that surround panning isn’t altered by a Balance parameter setting, check that the balance “dot” is in the center of the virtual head.
- Size lock. This maintains the same Size setting, regardless of what you do with the Direction and Spread parameters. Hold Shift to bypass Lock temporarily, and fine-tune Size.
- Object Panner. Right-click on the Surround panner, and you can choose an Object Panner instead. This is less relevant with stereo, because front/back and lower/higher directionality doesn’t exist like it does in a true Atmos system. However, the Object Panner does have Size, Spread, and Pan X (left/right) parameters, so feel free to play around with it—you may like the interface better than the surround panner. It’s also possible to do crazy automation moves. In any case, you can’t break anything.
- Other. This is another function you reach via a right-click on the Surround Panner. You’ll see a list of other plugins on your system that may have spatial placement abilities, like Waves’ Nx series of control room emulators, Brauer Motion, Ozone Imager, Ambisonics plugins, and the like. If you insert one of these, you can revert to the stock Studio One panners or choose other options by clicking on the downward arrow just under the “other” plugins name.
It may sound crazy to use Surround panners in stereo projects—but try it. You can truly do stereo panning like never before.
Presence Electric 12-String (the Artist Version Remix)

Presence’s sound library includes a fine acoustic 12-string guitar, but not an electric one. So, perhaps it’s not surprising that one of the more popular blog posts in this series was about how to create a realistic electric 12-string preset with Presence.
Unfortunately, that was before Studio One introduced Track Presets. The preset relied on a Multi Instrument, so it worked only with Studio One Professional. However, thanks to Track Presets, we can revisit our electric 12-string, and make a plug ’n’ play version that works for Studio One Artist as well as Professional (download link at the end).
Overcoming the Sampling Problem with 12 String Guitars
Sampling a 12-string is difficult. The sound is constantly changing due to the shimmering effect from slightly detuned strings. Furthermore, some notes are doubled with octave-higher notes, while other notes are doubled with unison notes. My solution is not to try and sample a 12-string guitar, but to construct one from three sets of 6-string guitar samples.
Each of the three Presence instances (fig. 1) loads the preset Guitar > Telecaster > Telecaster Open from the stock Presence library:
- One instance provides the main guitar sound.
- Transposing another instance up 12 semitones provides the octave-above notes.
- A physical 12-string guitar doesn’t have octaves on the 1st and 2nd strings, so the third Presence instance provides a unison sound for the higher strings.
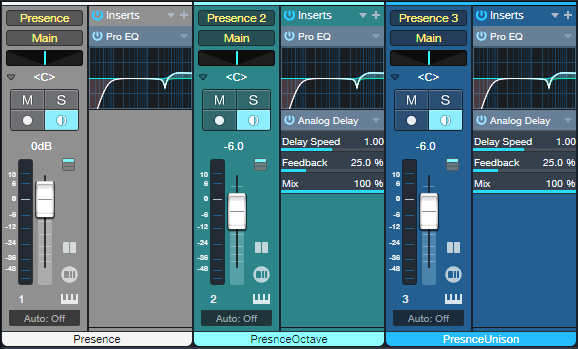
Figure 1: With three instances needed to create a single instrument, note that all three Monitor buttons must be enabled to play the instrument from your keyboard or MIDI guitar controller.
Limiting Note Ranges
In the original preset, Multi Instrument Range edits prevented the unison sounds from overlapping with the octave-above sounds. In the Artist preset, two Input Filter Note FX restrict the ranges (fig. 2).
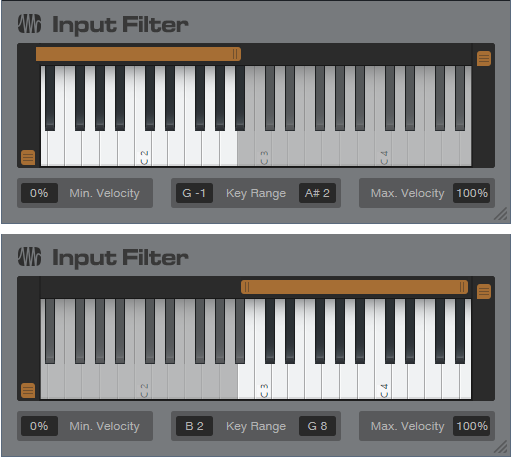
Figure 2: The upper Note FX Input Filter restricts the range of the octave-above notes to A#2 and below. The lower Note FX Input Filter restricts the range of the unison strings to B2 and above.
Emulating the 12-String “Shimmer”
A 12-string is never perfectly in tune, which gives a shimmering effect. The octave instance is transposed up +12 semitones, but the Pitch Fine Tune setting is +5 cents. The unison instance Pitch Fine Tune is -2 cents. This gives the chorus-like that’s inherent in 12-string guitars. Detuning the virtual strings provides a more realistic sound than trying to “fake it” with a time-based modulation effect.
About the Analog Delays
The higher string in a pair of strings plays just a little bit late, because your pick hits the main string before the octave or unison string. To emulate this effect, the Analog Delay (fig. 3) provides a 20 ms delay for the octave and unison instances. (We can’t use Presence’s Delay, because the mix needs to be 100% delay—no dry sound.)
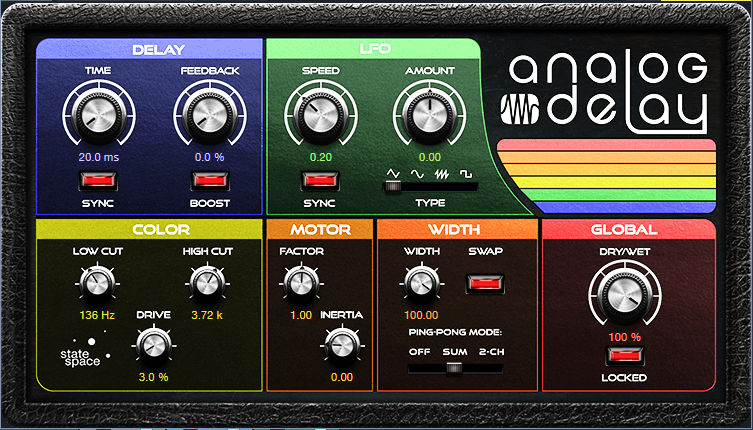
Figure 3: Analog Delay settings used to emulate string pluck delay.
Without this delay, the emulated 12-string lacks realism. The Analog Delay also adds some High Cut to reduce some of the brightness caused by transposing the octave strings. The Width settings provide a big stereo image, but for a more “normal” sound, turn ping-pong mode to Off.
The octave and unison instance levels are -6 dB below the main guitar sound. With physical 12-string guitars, the octave strings are thinner than the strings that generate the standard pitch. So, they generate less output. Lowering the level of the octave strings gives a better overall balance. Technically, the unison strings could be at the same level, but their levels are also a little lower to avoid an unbalanced sound compared to the octave strings.
EQ Settings
The Octave and Unison string instances use Presence’s internal EQ to attenuate the highest and lowest frequency bands. The main instance attenuates the low band, but peaks +3 dB at 3 kHz. Regarding the Pro EQ3 settings, open up the preset if you want to deconstruct the programming. The main aspects are a bass cut to give a more trebly, “Ricky”-like 12-string sound, a high-shelf boost for a little extra brightness, and a narrow notch around 3.2 kHz to reduce some “string ping” inherent in the original samples. As always, though, adjust for your tastes in guitar tone.
So, Studio One Artist aficionados, what are you waiting for? Download the preset, and get ready to make some cool electric 12-string sounds.
Download CA 12-String Electric Artist.trackpreset here!
Faster, Simpler, and Better Comping
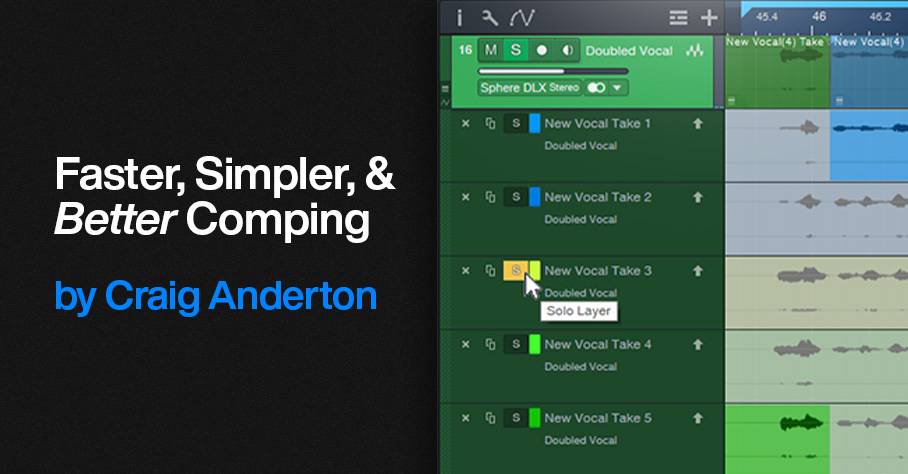
At first, this might not seem too exciting. But follow the directions below, and try comping using this method—I don’t think you’ll be disappointed. This tip shows how to:
- Audition, select sections of, and promote Takes while listening to the rest of the mix, at any level you want.
- Listen to the edited Parent track made up of the Takes you’ve promoted, at any time during the comping process. Again, this is in context with the mix.
- Do all of the above while looping, so there’s never a break in the editing process.
- Do comping with only the Arrow tool—you don’t need the Listen tool.
Preparation: Set Up Dim Solo
First, implement the Dim Solo function described in the blog post Super-Simple Dim Solo Functionality. Dim Solo allows soloing a track or tracks, while all the other tracks are at an adjustable lower level. The process works by assigning all tracks except for the one you want to solo (e.g., a vocal track with its Take layers) to a VCA channel. You can then “dim” all the non-soloed tracks with the VCA level fader to whatever level you want while you comp, and hear the Takes in context with the song. After auditioning and selecting the desired sections of your Takes, set the VCA fader back to 0.0 to return to the original mix levels. The minute or two it takes to set up Dim Solo is more than offset by the benefits it offers to comping. For more details, refer to this blog post for how to create the Dim Solo function.
Faster Take Auditioning, Selecting, and Promoting
After setting up Dim Solo and using the VCA Channel fader to adjust the level of the mix (which excludes the track being comped, because it isn’t part of the VCA group), here’s how to audition and select Takes:
1. Safe Solo (Shift+Click) the parent track with the Takes. This is important! It allows soloing the Parent track without muting the tracks that are playing back at the dimmed level.
2. Loop the section with the Takes you want to audition.
3. Click a Take’s Solo button to audition it while the song loops (fig. 1).
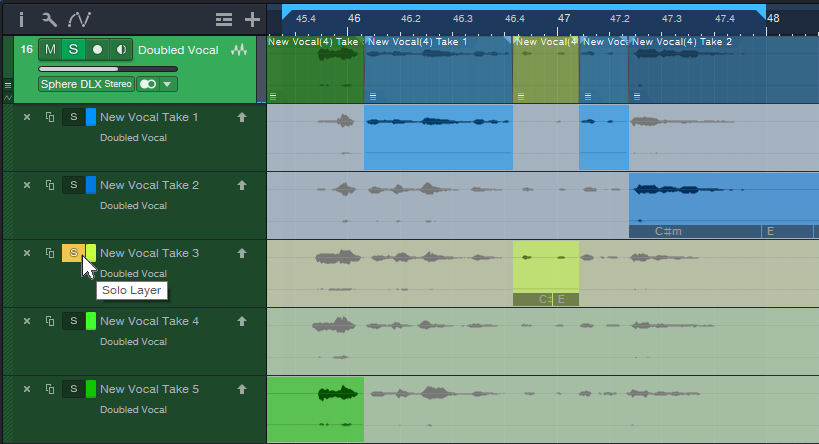
Figure 1: Take 3 is being soloed for auditioning, and for selecting sections to be promoted to the Parent track. Turning off the Take’s Solo would solo the Parent track, so you could audition the edited parent track and hear any Take sections that had been promoted.
4. If you hear a section in a Take you want to promote to the Parent track, use the Arrow tool (which turns into an I-beam cursor when hovering over a selected Take) to click+drag over the section.
5. Continue soloing Takes while the music loops, and select the sections you want to promote to the Parent track. If needed, alter the loop start and end points.
6. If at any time you want to hear the edited Parent Track with the Takes you’ve promoted up to that point, make sure no Take layers are in solo mode.
Better Music Through Better Comping
One reason I wrote up this tip is because of an interesting side effect. The Takes I selected as “best” when auditioned in the usual way were often not the same Takes chosen as “best” when listening to them in context with the music. A technically perfect Take is not necessarily the same thing as a Take with the best feel. Listening to, selecting, and promoting the Takes in context with the mix makes a big difference in helping to select Takes that fit the music like a glove.