Monthly Archives: May 2023
The Surprising Channel Strip EQ

Announcement: Version 1.4.1 of The Huge Book of Studio One Tips and Tricks is a free update to owners of previous versions. Simply download the book again from your PreSonus account, and it will be the most recent version. This is a “hotfix” update for improved compatibility with Adobe Acrobat’s navigation functions. The content is the same as version 1.4.
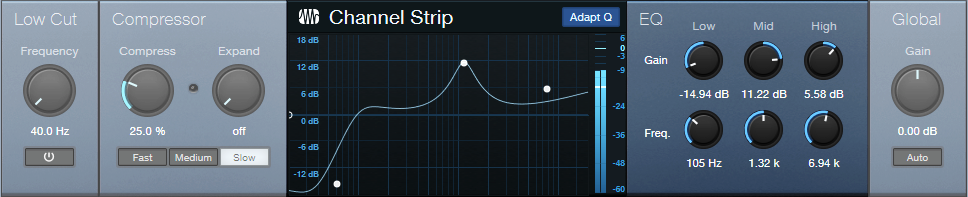
Studio One has a solid repertoire of EQs: the Fat Channel EQs, Pro EQ3, Ampire’s Graphic Equalizer, and the Autofilter. Even the Multiband Dynamics can serve as a hip graphic EQ. With this wealth of EQs, it’s potentially easy to overlook the Channel Strip’s EQ section (fig. 1). Yet it’s significantly different from the other EQs.
Back to the 60s
In the late 60s, Saul Walker (API’s founder) introduced the concept of “proportional Q” in API equalizers. To this day, engineers praise API equalizers for their “musical” sound, and much of this relates to proportional Q.
The theory is simple. At lower gains, the bandwidth is wider. At higher gains, it becomes narrower. This is consistent with how we often use EQ. Lower gain settings are common for tone-shaping. Increasing the gain likely means you want a more focused effect.
The concept works similarly for cutting. If you’re applying a deep cut, you probably want to solve a problem. A broad cut is more about shaping tone. Also, because cutting mirrors the response of boosting, proportional Q equalizers make it easy to “undo” equalization settings. For example, if you boosted drums around 2 kHz by 6 dB, cutting by 3 dB produces the same curve as if the drums had originally been boosted by 3 dB.
Proportional Q also works well with vocals and automation. For less intense parts, add a little gain in the 2-4 kHz range. When the vocal needs to cut through, raise the gain to increase the resonance and articulation.
The Channel Strip’s Adapt Q button converts the response to proportional Q. Let’s look at how proportional Q affects the various responses.
High and Low Stages
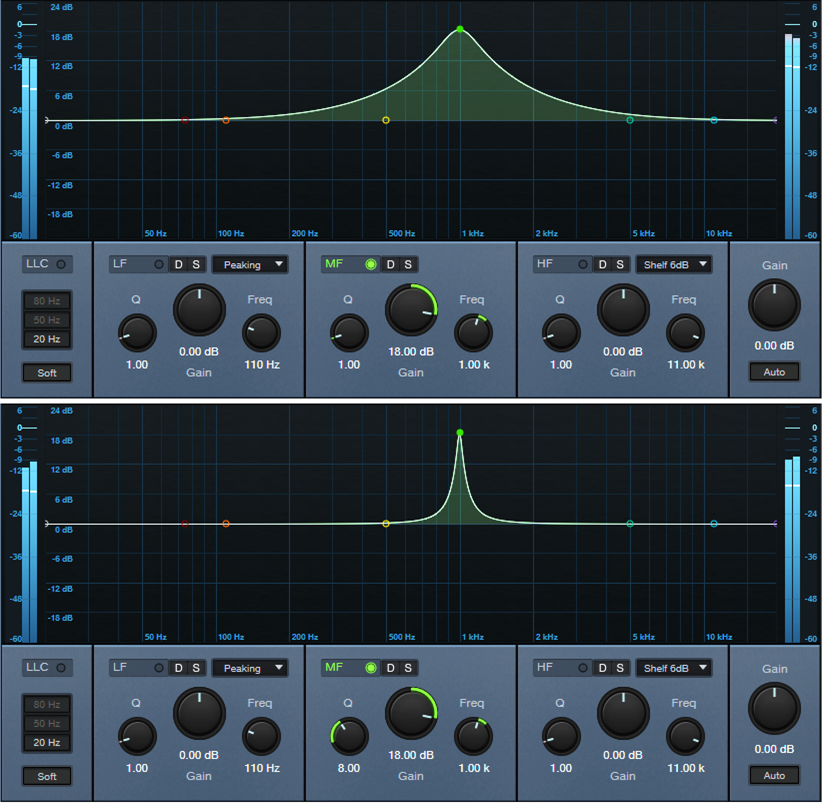
The High band is a 12 dB/octave high shelf. In fig. 2, the Boost is +15 dB, at a frequency of 2.5 kHz. The top image shows the EQ without Adapt Q. The lower image engages Adapt Q, which increases the shelf’s resonance.
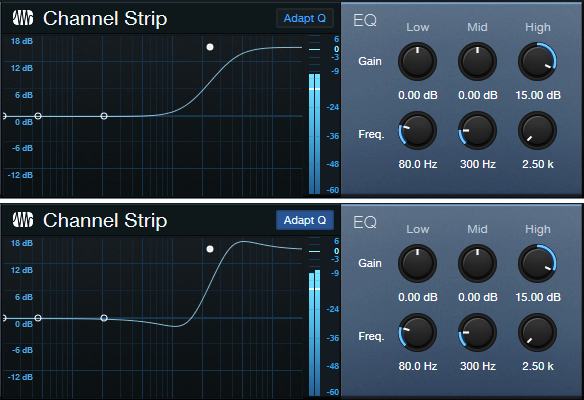
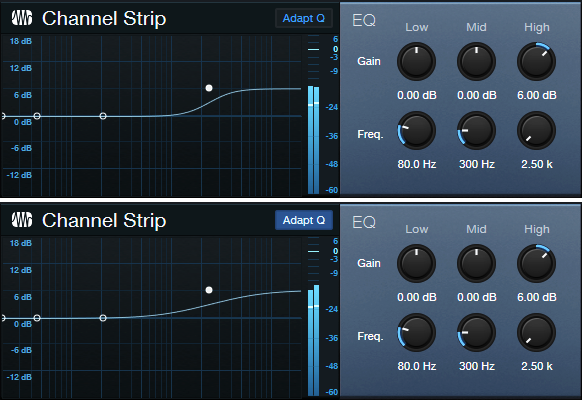
Fig. 3 shows what happens with 6 dB of gain. With Adapt Q enabled, the Q is actually less than the corresponding amount of Q without Adapt Q.
Cutting flips the curve vertically, but the shape is the same. With the Low shelf filter, the response is the mirror image of the High shelf.
Midrange Stage
The Midrange EQ stage has variable Gain and Frequency. There’s no Q control, but the filter works with Adapt Q to increase Q with more gain or cut (fig. 4).
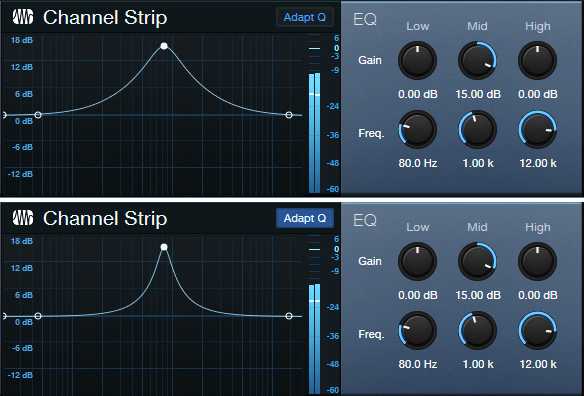
With 6 dB Gain, the Q is essentially the same, regardless of the Adapt Q setting (fig. 5).

Finally, another Adapt Q characteristic is that the midrange section’s slope down from either side of the peak (called the “skirt”) hits the minimum amount of gain at the same upper and lower frequencies, regardless of the gain. This is different from a traditional EQ like the Pro EQ3, where the skirt narrows with more Q (fig. 6).
Perhaps best of all, the Channel Strip draws very little CPU power. So, if you need more stages of EQ, go ahead and insert several Channel Strips in series, or in parallel using a Splitter or buses. And don’t forget—the Channel Strip also has dynamics 😊!
Set Up the Quantum Interface Preamps with One Track
A single Automation track can set up a session’s preamp levels and phantom power in the Quantum interface, as well as the older Studio 192. So, you can stop taking the time to reset preamp levels if you do lots of different sessions—let Studio One set up the preamps whenever you call up a specific song.
For example, I mostly use three vocal mics. However, their optimum gain settings vary for narration, music vocals, or recording my main background vocalist—who needs different gain settings depending on whether she’s doing upfront vocals, or ooohs/ahhhs.
To call up specific preamp levels for different songs, simply create an automation track (or tracks) at the song’s beginning. Then, when you first hit record, the track sets up levels and (with Quantum and Studio 192) phantom power on/off for up to 8 channels. The next time you call up that song, the mics will be at the right levels, with phantom power set as desired. Here’s how to do it.
1. In Universal Control, under MIDI Control, select Internal. Or, choose Enabled if you also want to be able to control Quantum from an external controller.
2. Choose Studio One > Options (Windows) or Preferences (macOS), and select External Devices.
3. Select Add. Choose New Instrument.
4. For Receive From, choose Quantum MIDI In. For Send To, choose Quantum MIDI Out. Also tick MIDI Channels 1 – 8 (fig. 1). Then, click OK.
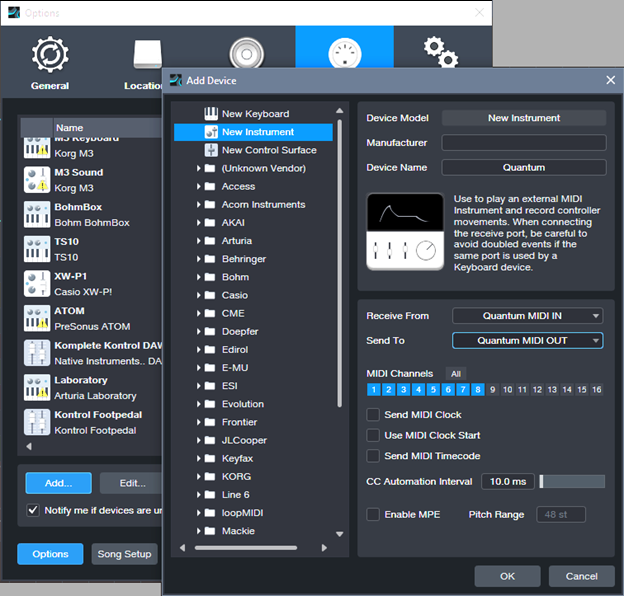
5. Create an Automation track. To show automation, type keyboard shortcut A.
6. From the track’s automation drop-down menu, click on Add/Remove. In the right pane, unfold the External Devices folder, then unfold the folder for the Channel that corresponds to the preamp you want to control (Channel 1 = Preamp 1, Channel 2 = Preamp 2…Channel 8 = Preamp 8). See fig. 2.
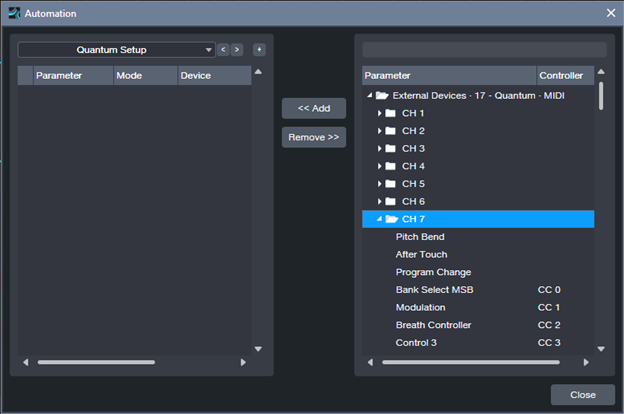
7. For each preamp you want to set up, add CC7 (this controls preamp volume) and CC14 (controls phantom power). For example, I typically set up channels 6, 7, and 8. After adding these continuous controllers, the Automation menu’s right side looks like fig. 3 (except with your specific channel numbers). Click on Close after making your selections.

8. To set up the preamp levels, choose the parameter you want to program in the Automation track’s drop-down menu. Note that in the documentation, the phantom power control settings are reversed. The correct values for CC14 are 0 to 63 = Off, and 64 to 127 = On. To set the preamp level, with Universal Control open, adjust the envelope for the desired preamp gain reading (you can also see the level on the Quantum’s display).
9. Set the initial level and phantom power parameter values for the chosen preamps. Now your automation track will reproduce those settings, exactly as programmed, the next time you open the song. Given that I do voiceover or narration for at least one video a week, I can’t tell you how much time that saves—I load my narration template, and don’t even have to think about adjusting levels before hitting record.
Getting Fancy
A cool trick is to reserve a song’s first measure for doing the setup. Turn on phantom power at the song start, but fade up the volume to the desired level after the phantom power is on. That avoids power-on spikes from the mics. However, when adjusting the level envelope, the preamp knobs change only if you adjust the left-most node. So, set the preamp level you want with this node, then move it to the right on the timeline. Create another node at 0 that fades up to the node you moved, which sets the final volume.
Another trick is to have more than one automation track. For example, on most songs I have a setup track for me, and a setup track for the background singer. When she does overdubs, I turn my automation track to Off, and set her automation track to Read so it sets her levels.
Coda: Windows Meets Thunderbolt
The first time I tried Quantum on a Mac, it worked perfectly. With Windows, well…it’s Windows. My computer is a PC Audio Labs Rok Box (great machine, by the way) with dual Thunderbolt 3 ports. I used Apple’s TB3-to-TB2 adapter—no go. I found a new Thunderbolt driver for the motherboard, and asked PC Audio Labs tech support about whether I should install it. They advised doing so, and said if I had problems, they’d bail me out. But after installation, the Quantum’s power button’s color was still Unhappy Red instead of Happy Blue. I was about to contact support again, but stumbled on a program in the computer called Thunderbolt Control Center. I opened it, which showed Quantum was connected—but I hadn’t given the computer “permission” to connect. So, I gave permission. With its new-found freedom, the Quantum burst into its low-latency glory.
The moral of the story: Thunderbolt has many variables on Windows than macOS. But as with life itself, perseverance furthers.
The “Drenched” Chorus
Studio One’s chorus gives the “wet” sound associated with chorus effects. But I wanted a chorus that went beyond wet to drenched—something that could swirl in the background of a thick arrangement, and shower the stereo field like a sprinkler system. Check out the audio example: the first part is the Drenched Chorus, and the second part is the standard Chorus.
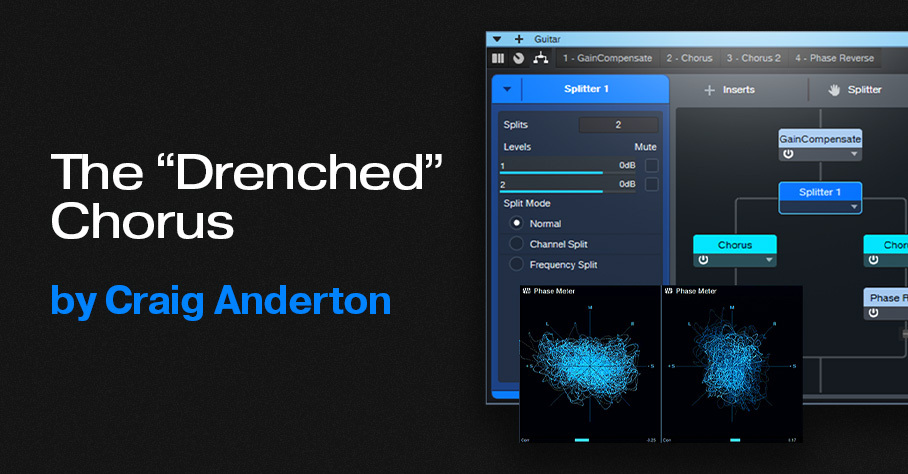
This FX Chain for Studio One Professional (see the download link at the end) supercharges the wet sound by inserting two choruses in parallel, and reversing the phase for one of them (fig. 1). This cancels any dry sound, leaving only the animation from the stereo chorus. A Mixtool provides the phase reversal. Another Mixtool at the input adds gain, to compensate for the level that’s lost through phase cancellation.
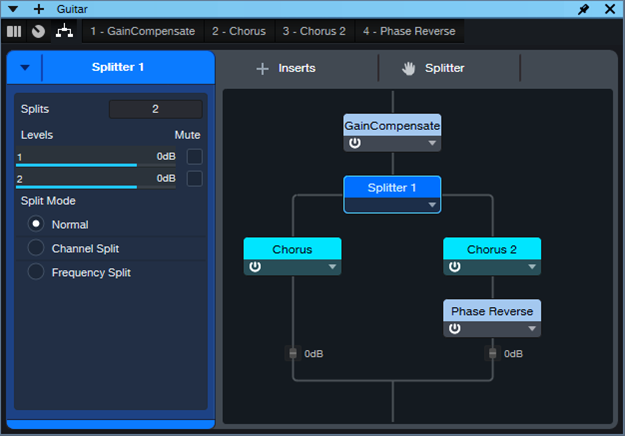
The Choruses are essentially set to the default preset, but with Low Freq at minimum and High Freq at maximum for the widest frequency response. Fig. 2 uses a phase meter to compare the Drenched Chorus (left) with the standard Chorus (right), playing the same section of a guitar part. Note how the Drenched Chorus puts a lot of energy into the sides, which accounts for the big stereo image. Meanwhile, the center has less level than the standard chorus, due to any vestiges of dry signal being removed.
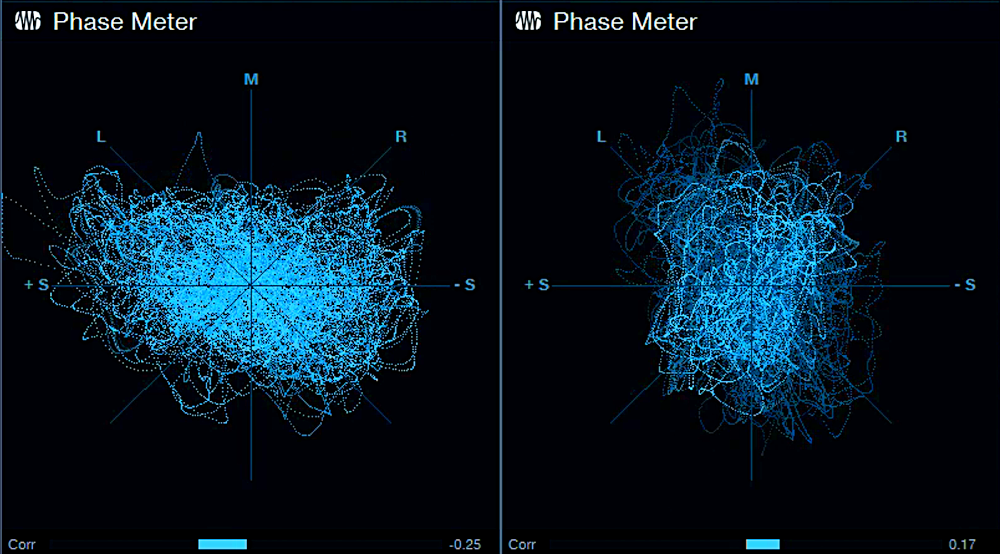
This effect is designed for stereo playback, but note that in fig. 2, the Drenched Chorus’s correlation is negative. Normally you want to avoid this, because audio with negative correlation will cancel when played back in mono. However, the correlation swings wildly between positive and negative, so it’s not much of an issue. With mono playback, all that happens is a slight level loss due to occasional negative correlations. The effect still sounds like a chorus, although of course you lose the cool stereo effects.
How to Use It
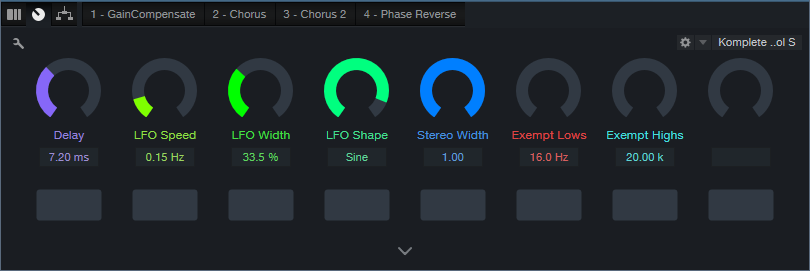
Download the FX Chain, and drag it into a channel’s insert. The Macro Controls (fig. 3) affect only Chorus 2. Here’s what they do:
- Delay: Set this to 9.00 for maximum cancellation. The sound is somewhat like a combination of chorusing and flanging. Offsetting from this time increases the chorus effect. The maximum Drenched Chorus effect occurs between approximately 7 and 11 ms.
- LFO Speed: I prefer settings below 0.30 Hz, but higher settings have a bit of a rotating speaker vibe.
- LFO Width: More Width increases the chorusing effect. If you turn this up, I recommend keeping LFO Speed below 0.30 Hz.
- LFO Shape: Setting this to Triangle uses the same shape as the other Chorus. Sine gives a subtly different sound.
- Stereo Width: Extends the stereo image outward when turned clockwise.
- Exempt Lows: This turns up the Low Freq filter, which reduces cancellation at those frequencies. Use this when you want more of the direct sound instead of maximum drenching.
- Exempt Highs: This turns down the High Freq filter, which reduces cancellation at those frequencies. Personally, I leave both controls all the way down for maximum moisture, but turn them up if you want the track to swim a little less in the background.
Download the FX Chain below!
Solve Vocal Problems with the De-Esser
Studio One offers several ways to “de-ess” excessive sibilants (“s” sounds). De-essing combines compression and EQ. The EQ focuses on the frequency range where sibilants are most prominent. Then, compression reduces this range’s level when sibilants are present. Prior to version 6, using Multiband Dynamics was the best way to do de-essing.
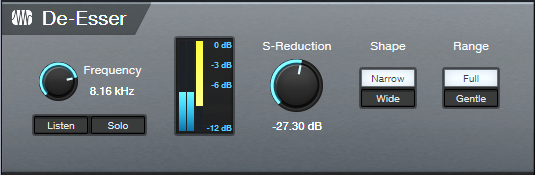
With version 6, the Pro EQ3’s new dynamic EQ functionality is excellent for reducing ess sounds. However, the equally new De-Esser (fig. 1) is designed specifically for the job of fixing excessive sibilance, quickly and effectively.
To get the most out of the De-Esser, note that some of the parameters work together as a team. So, alternating edits between some controls is often the best way to optimize the effect.
Getting Started
Ess sounds tend to be short. By the time you’ve started to tweak a parameter, the ess sound has likely already ended. So, for easy editing, create a short loop on a word with the prominent ess sound.
Frequency and Listen
1. Enable Listen.
2. Vary Frequency until you find the frequency where the ess sound is most prominent.
Solo and S-Reduction
3. After identifying the frequency, enable Solo. You’ll hear only the ess sound whose volume is being reduced.
4. Adjust S-Reduction to get a feel for the optimum ess reduction amount. At 0.00 dB, there’s no reduction. At ‑60.00, sounds in addition to the ess sound will likely be reduced.
5. Next, turn off Solo, and adjust S-Reduction in context with the looped word. Less negative S-Reduction values concentrate on reducing the ess sound’s initial transient. More negative values reduce more of the ess sound past the initial transient.
6. Do a final Frequency parameter check to optimize the high-frequency response with de-essing. For example, you may be able to raise the frequency to retain more highs, yet still have effective ess reduction.
The metering is helpful in optimizing the De-Esser’s settings. The orange meter shows the amount of reduction. The blue meter shows the input level.
How to Use the Shape Parameter
Ess sounds cover a fairly small range of high frequencies. The Narrow Shape is best for this application because it compresses a narrow band. Frequencies above and below that band remain untouched.
In addition to ess sounds, the De-Esser can also reduce “shhh” sounds (e.g., like the shh sound in “action” or “compression”). Shh sounds cover a wider range of frequencies, and often require a lower Frequency setting. For these sounds, the Wide Shape splits the audio into high and low bands, and processes the entire high band.
You may need to do two passes, one with a Wide Shape for shh sounds, and one with a Narrow Shape for ess sounds. Be conservative with the settings for the two passes, because the changes will reinforce each other.
How to Use the Range Parameter
This parameter is the De-Esser’s unsung hero. Setting Range to Full allows the full amount of reduction dialed in by S-Reduction. Gentle Range restricts reduction to ‑6 dB.
The Gentle setting is useful for more than just guaranteeing a subtler effect. With the Gentle Range enabled, you can dial in huge amounts of S-Reduction. This allows processing as much of the ess or shh sound as possible, not just the initial transient. However, limiting the amount of reduction to -6 dB prevents the amount of reduction from being objectionable.
Final Note
The De-Esser is not just for singing, but also podcasts, voiceovers, and narration. It can even reduce harshness with amp sims, as described in De-Esser Meets Amp Sims. And it can probably do other things that are yet to be discovered!